|
pyclustering
0.10.1
pyclustring is a Python, C++ data mining library.
|
|
pyclustering
0.10.1
pyclustring is a Python, C++ data mining library.
|
Class represents agglomerative algorithm for cluster analysis. More...
Public Member Functions | |
| def | __init__ (self, data, number_clusters, link=None, ccore=True) |
| Constructor of agglomerative hierarchical algorithm. More... | |
| def | process (self) |
| Performs cluster analysis in line with rules of agglomerative algorithm and similarity. More... | |
| def | get_clusters (self) |
| Returns list of allocated clusters, each cluster contains indexes of objects in list of data. More... | |
| def | get_cluster_encoding (self) |
| Returns clustering result representation type that indicate how clusters are encoded. More... | |
Class represents agglomerative algorithm for cluster analysis.
Agglomerative algorithm considers each data point (object) as a separate cluster at the beginning and step by step finds the best pair of clusters for merge until required amount of clusters is obtained.
Example of agglomerative algorithm where centroid link is used:
There is example of clustering 'LSUN' sample:
Example of agglomerative clustering using different links:
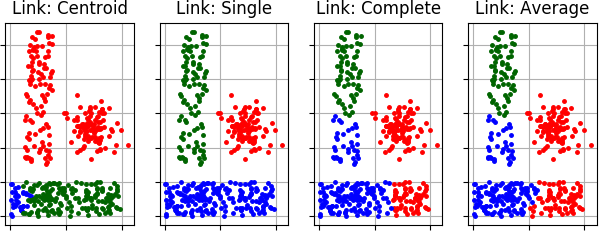
Definition at line 43 of file agglomerative.py.
| def pyclustering.cluster.agglomerative.agglomerative.__init__ | ( | self, | |
| data, | |||
| number_clusters, | |||
link = None, |
|||
ccore = True |
|||
| ) |
Constructor of agglomerative hierarchical algorithm.
| [in] | data | (list): Input data that is presented as a list of points (objects), each point should be represented by list, for example [[0.1, 0.2], [0.4, 0.5], [1.3, 0.9]]. |
| [in] | number_clusters | (uint): Number of clusters that should be allocated. |
| [in] | link | (type_link): Link type that is used for calculation similarity between objects and clusters, if it is not specified centroid link will be used by default. |
| [in] | ccore | (bool): Defines should be CCORE (C++ pyclustering library) used instead of Python code or not (by default it is 'False'). |
Definition at line 102 of file agglomerative.py.
| def pyclustering.cluster.agglomerative.agglomerative.get_cluster_encoding | ( | self | ) |
Returns clustering result representation type that indicate how clusters are encoded.
Definition at line 172 of file agglomerative.py.
| def pyclustering.cluster.agglomerative.agglomerative.get_clusters | ( | self | ) |
Returns list of allocated clusters, each cluster contains indexes of objects in list of data.
Definition at line 157 of file agglomerative.py.
Referenced by pyclustering.samples.answer_reader.get_cluster_lengths(), and pyclustering.cluster.optics.optics.process().
| def pyclustering.cluster.agglomerative.agglomerative.process | ( | self | ) |
Performs cluster analysis in line with rules of agglomerative algorithm and similarity.
Definition at line 132 of file agglomerative.py.
 1.8.17
1.8.17