|
pyclustering
0.10.1
pyclustring is a Python, C++ data mining library.
|
|
pyclustering
0.10.1
pyclustring is a Python, C++ data mining library.
|
Class implements K-Means clustering algorithm. More...
Public Member Functions | |
| def | __init__ (self, data, initial_centers, tolerance=0.001, ccore=True, **kwargs) |
| Constructor of clustering algorithm K-Means. More... | |
| def | process (self) |
| Performs cluster analysis in line with rules of K-Means algorithm. More... | |
| def | predict (self, points) |
| Calculates the closest cluster to each point. More... | |
| def | get_clusters (self) |
| Returns list of allocated clusters, each cluster contains indexes of objects in list of data. More... | |
| def | get_centers (self) |
| Returns list of centers of allocated clusters. More... | |
| def | get_total_wce (self) |
| Returns sum of metric errors that depends on metric that was used for clustering (by default SSE - Sum of Squared Errors). More... | |
| def | get_cluster_encoding (self) |
| Returns clustering result representation type that indicate how clusters are encoded. More... | |
Class implements K-Means clustering algorithm.
K-Means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells.
K-Means clustering results depend on initial centers. Algorithm K-Means++ can used for initialization of initial centers - see module 'pyclustering.cluster.center_initializer'.
CCORE implementation (C/C++ part of the library) of the algorithm performs parallel processing to ensure maximum performance.
Implementation based on the paper [26].
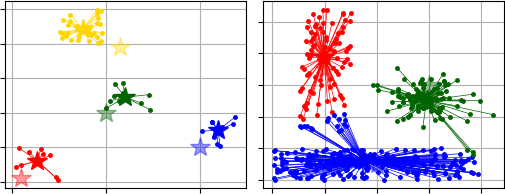
Example #1 - Clustering using K-Means++ for center initialization:
Example #2 - Clustering using specific distance metric, for example, Manhattan distance:
| def pyclustering.cluster.kmeans.kmeans.__init__ | ( | self, | |
| data, | |||
| initial_centers, | |||
tolerance = 0.001, |
|||
ccore = True, |
|||
| ** | kwargs | ||
| ) |
Constructor of clustering algorithm K-Means.
Center initializer can be used for creating initial centers, for example, K-Means++ method.
| [in] | data | (array_like): Input data that is presented as array of points (objects), each point should be represented by array_like data structure. |
| [in] | initial_centers | (array_like): Initial coordinates of centers of clusters that are represented by array_like data structure: [center1, center2, ...]. |
| [in] | tolerance | (double): Stop condition: if maximum value of change of centers of clusters is less than tolerance then algorithm stops processing. |
| [in] | ccore | (bool): Defines should be CCORE library (C++ pyclustering library) used instead of Python code or not. |
| [in] | **kwargs | Arbitrary keyword arguments (available arguments: 'observer', 'metric', 'itermax'). |
Keyword Args:
| def pyclustering.cluster.kmeans.kmeans.get_centers | ( | self | ) |
Returns list of centers of allocated clusters.
| def pyclustering.cluster.kmeans.kmeans.get_cluster_encoding | ( | self | ) |
Returns clustering result representation type that indicate how clusters are encoded.
| def pyclustering.cluster.kmeans.kmeans.get_clusters | ( | self | ) |
Returns list of allocated clusters, each cluster contains indexes of objects in list of data.
Definition at line 450 of file kmeans.py.
Referenced by pyclustering.samples.answer_reader.get_cluster_lengths(), and pyclustering.cluster.optics.optics.process().
| def pyclustering.cluster.kmeans.kmeans.get_total_wce | ( | self | ) |
Returns sum of metric errors that depends on metric that was used for clustering (by default SSE - Sum of Squared Errors).
Sum of metric errors is calculated using distance between point and its center:
\[error=\sum_{i=0}^{N}distance(x_{i}-center(x_{i}))\]
| def pyclustering.cluster.kmeans.kmeans.predict | ( | self, | |
| points | |||
| ) |
Calculates the closest cluster to each point.
| [in] | points | (array_like): Points for which closest clusters are calculated. |
| def pyclustering.cluster.kmeans.kmeans.process | ( | self | ) |
Performs cluster analysis in line with rules of K-Means algorithm.
 1.8.17
1.8.17