|
pyclustering
0.10.1
pyclustring is a Python, C++ data mining library.
|
|
pyclustering
0.10.1
pyclustring is a Python, C++ data mining library.
|
K-Means++ is an algorithm for choosing the initial centers for algorithms like K-Means or X-Means. More...
Public Member Functions | |
| def | __init__ (self, data, amount_centers, amount_candidates=None, **kwargs) |
| Creates K-Means++ center initializer instance. More... | |
| def | initialize (self, **kwargs) |
| Calculates initial centers using K-Means++ method. More... | |
Static Public Attributes | |
| string | FARTHEST_CENTER_CANDIDATE = "farthest" |
| Constant denotes that only points with highest probabilities should be considered as centers. | |
K-Means++ is an algorithm for choosing the initial centers for algorithms like K-Means or X-Means.
K-Means++ algorithm guarantees an approximation ratio O(log k). Clustering results are depends on initial centers in case of K-Means algorithm and even in case of X-Means. This method is used to find out optimal initial centers.
Algorithm can be divided into three steps. The first center is chosen from input data randomly with uniform distribution at the first step. At the second, probability to being center is calculated for each point:
\[p_{i}=\frac{D(x_{i})}{\sum_{j=0}^{N}D(x_{j})}\]
where \(D(x_{i})\) is a distance from point \(i\) to the closest center. Using this probabilities next center is chosen. The last step is repeated until required amount of centers is initialized.
Pyclustering implementation of the algorithm provides feature to consider several candidates on the second step, for example:
If the farthest points should be used as centers then special constant 'FARTHEST_CENTER_CANDIDATE' should be used for that purpose, for example:
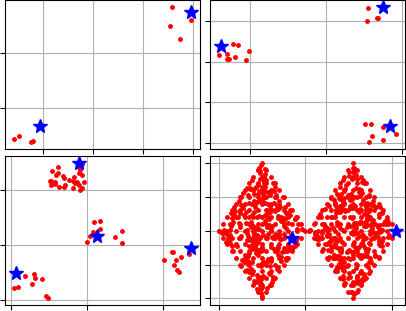
There is an example of initial centers that were calculated by the K-Means++ method:
Code example where initial centers are prepared for K-Means algorithm:
Definition at line 95 of file center_initializer.py.
| def pyclustering.cluster.center_initializer.kmeans_plusplus_initializer.__init__ | ( | self, | |
| data, | |||
| amount_centers, | |||
amount_candidates = None, |
|||
| ** | kwargs | ||
| ) |
Creates K-Means++ center initializer instance.
| [in] | data | (array_like): List of points where each point is represented by list of coordinates. |
| [in] | amount_centers | (uint): Amount of centers that should be initialized. |
| [in] | amount_candidates | (uint): Amount of candidates that is considered as a center, if the farthest points (with the highest probability) should be considered as centers then special constant should be used 'FARTHEST_CENTER_CANDIDATE'. By default the amount of candidates is 3. |
| [in] | **kwargs | Arbitrary keyword arguments (available arguments: 'random_state'). |
Keyword Args:
None, current system time is used).Definition at line 164 of file center_initializer.py.
| def pyclustering.cluster.center_initializer.kmeans_plusplus_initializer.initialize | ( | self, | |
| ** | kwargs | ||
| ) |
Calculates initial centers using K-Means++ method.
| [in] | **kwargs | Arbitrary keyword arguments (available arguments: 'return_index'). |
Keyword Args:
Definition at line 329 of file center_initializer.py.
 1.8.17
1.8.17