Represent algorithm for searching optimal number of clusters using specified K-algorithm (K-Means, K-Medians, K-Medoids) that is based on Silhouette method. More...
Public Member Functions | |
| def | __init__ (self, data, kmin, kmax, kwargs) |
| Initialize Silhouette search algorithm to find out optimal amount of clusters. More... | |
| def | process (self) |
| Performs analysis to find optimal amount of clusters. More... | |
| def | get_amount (self) |
| Returns optimal amount of clusters that has been found during analysis. More... | |
| def | get_score (self) |
| Returns silhouette score that belongs to optimal amount of clusters (k). More... | |
| def | get_scores (self) |
| Returns silhouette score for each K value (amount of clusters). More... | |
Represent algorithm for searching optimal number of clusters using specified K-algorithm (K-Means, K-Medians, K-Medoids) that is based on Silhouette method.
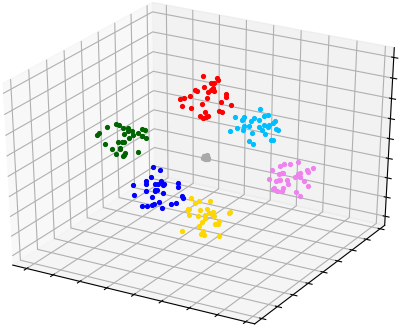
This algorithm uses average value of scores for estimation and applicable for clusters that are well separated. Here is an example where clusters are well separated (sample 'Hepta'):
Obtained Silhouette scores for each K:
K = 7 has the bigger average Silhouette score and it means that it is optimal amount of clusters:
Definition at line 305 of file silhouette.py.
| def pyclustering.cluster.silhouette.silhouette_ksearch.__init__ | ( | self, | |
| data, | |||
| kmin, | |||
| kmax, | |||
| kwargs | |||
| ) |
Initialize Silhouette search algorithm to find out optimal amount of clusters.
| [in] | data | (array_like): Input data that is used for searching optimal amount of clusters. |
| [in] | kmin | (uint): Amount of clusters from which search is performed. Should be equal or greater than 2. |
| [in] | kmax | (uint): Amount of clusters to which search is performed. Should be equal or less than amount of points in input data. |
| [in] | **kwargs | Arbitrary keyword arguments (available arguments: 'algorithm'). |
Keyword Args:
Definition at line 350 of file silhouette.py.
| def pyclustering.cluster.silhouette.silhouette_ksearch.get_amount | ( | self | ) |
Returns optimal amount of clusters that has been found during analysis.
Definition at line 435 of file silhouette.py.
| def pyclustering.cluster.silhouette.silhouette_ksearch.get_score | ( | self | ) |
Returns silhouette score that belongs to optimal amount of clusters (k).
Definition at line 447 of file silhouette.py.
Referenced by pyclustering.cluster.silhouette.silhouette_ksearch.process().
| def pyclustering.cluster.silhouette.silhouette_ksearch.get_scores | ( | self | ) |
Returns silhouette score for each K value (amount of clusters).
Definition at line 459 of file silhouette.py.
| def pyclustering.cluster.silhouette.silhouette_ksearch.process | ( | self | ) |
Performs analysis to find optimal amount of clusters.
Definition at line 384 of file silhouette.py.
Referenced by pyclustering.cluster.silhouette.silhouette_ksearch.get_scores().
 1.8.14
1.8.14